Chapter 2: The Digital
#
Chapter 2: The Digital
Alright, now onto the fun stuff, I think I’ve established that the physical side of how we use a computer is sub optimal, but what about how we actually do the things we do day to day? I think, for the most part, these things can be put into a few categories:
- Finding and Accessing shit
- Looking at shit
- Storing Shit
- Transferring Shit
- Making Shit
Finding and Accessing Information Sucks #
Search sucks #
If you’re like most people, you probably use Google Search, but also don’t like Google Search. Google’s search makes the entire top of the page ads, tracks you, and is just generally a bit invasive, but, you still probably use it instead of DuckDuckGo because the results often get you to what you’re looking for faster.
To some extent things have gotten better as it is gotten easier to search directly from the search bar, with more browsers supporting setting the search engine by a prefix in the url bar, so if, for example, I want to search Wikipedia and directly go to an article, I can just put a ‘w’ before what I search:
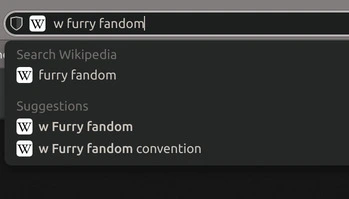
And this definitely helps, but it’s also not enough.
Search now regularly returns a number of results that is completely unprocessable by the human brain
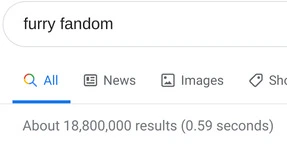
So, what can be done about this? Well, there’s already a fair amount of advanced search options:
But I honestly think these more or less miss the point of how people want to search, not to mention they’re not super easy to remember. Being able to take things out in large swaths is often rather helpful, so why are there not options like NO_SOCIAL to get rid of all social media results.
On a similar note, Ask HN: Is there a search engine which excludes the world’s biggest websites? was posted a while back, and I agree with idea: often I can find better information on smaller sites, so I think there should be an option to just say NO_10K to drop the top 10 thousand most popular sites from the search results. I don’t know if this is really the right way to do this though. Fortunately, I do think the resurgence of Webrings is improving that a bit.
Finding something when you don’t know the word for it exactly can be challenging too, especially if the correct term is also shared with something else (like looking for skateboard trucks but only searching the word ‘Trucks’). This wouldn’t be so bad, but sometimes trying to filter out the incorrect results doesn’t work either, because of unforeseen overlaps. Unfortunately I don’t know of a solution to this problem, as it’s one of conveying intent with context, something which has been a problem much longer than the existence of search engines.
Often, I find what I’m looking for faster by just going to as close of a topic as I can think of on Wikipedia and poking around links than I can by directly searching.
It’d also be nice to have the ability to just set a list of bad sites. Like, please never ever show me any results from Pintrest.
Thinking more into the future, I would very much like to see a world where data searching is context aware. For example, say I’m searching for a data sheet for an old vacuum tube and I have a schematic of an old amplifier open in another tab, I would love if the browser saw the context and changed the label in the schematic into a link to this datasheet. Furthermore, it would be great if it crawled the web and finished finding datasheets and linking them, possibly well before I even got to that page in the first place. I know we don’t have the tech to do this yet, especially not as a general purpose tool, but I like to think about the future. ¯\_(ツ)_/¯
Another point is the summery of information and omission of the irrelevant info. Say I were to look up bits in a byte, I don’t necessarily need the historical context as to why bits are named bits and bytes, bytes, though even though I didn’t search it, presenting that a nybble is 4 bits, and how to tell endinan-ness is more relevant, unless I had recently searched historical information or stated I wanted that explicitly. In my opinion we should be less concerned with finding relevant results and more concerned with discarding the irrelevant, though making the verbose available.
I also think that bringing people together, potentially anonymously, based on search and knowledge could be extraordinary valuable. If as I’m looking up ‘How to do X’ and somebody else is looking up ‘How to Do Y, an advanced topic from X’ it would be fantastic if we could talk, albeit unobtrusively to the person being requested. It seems to me that searching is desperately lacking a social element and ranking system. How great would a simple Reddit like upvote system on any given search be? What if browsers added a comment system that was hosted though some sort of distributed network and tied to each page so people could leave comments on any site regardless of if the site has comment functionality built in? (Yes, I know this is ripe for spam and abuse, but let me dream…)
Google also needs to quit their shit with information cards:
— Randall Munroe (@xkcd) December 1, 2020
And it’d be great if something could actually be done about big sites like Pinterest and Quora gaming Google.
There is some progress being made here, as Google Says AI Generated Content Is Against Guidelines; however, a user on Hacker News had an interesting take on this:
This internal tension between chasing AI tooling and avoiding AI-generated content is just a prelude to the bigger shift of search engines getting reinvented around generated results instead of found results. Fast forward 10+ years and for knowledge-related queries search is going to be more about generated results personalized to our level of understanding that at best quote pages, and more likely just reference them in footnotes as primary inputs.
These knowledge-related queries are where most content farms, low quality blogs, and even many news sites get traffic from today. If the balance of power between offense (generating AI content) and defense (detecting AI content) continues to favor offense, there will be a strong incentive to just throw the whole thing out and go all-in on generated results.
Big question is how incentives play out for the people gathering the knowledge about the world, which is the basis for generated results. Right now many/most make money with advertising, but so do content farms, and more generated results means more starving of that revenue source. For a portion of info that people want to know (e.g. factual info, not opinions, guidance, etc), Wikipedia is an alternative fact- and context-gathering model, but if search relies on it more, it will strain Wikipedia’s governance model and become more of a single point of failure.
Really interesting stuff ahead.
- npunt on Hacker News
Finally, I do want to end on a positive note: Google is trying to show why results are ranked how they are, and that’s actually pretty cool - though it does still seem that search results are getting worse, at least according to Hacker News users. Fortunately, there are interesting search engines, both general purpose like you.com and more specific, like lieu for searching the XXIIVV webring or the data-oriented WolframAlpha. There’s also the neat Hypersearch extension which does make google search at least a bit better. Speaking of, the author of Hypersearch has a great blog post on the subject: If Google sucks then why is everyone still using it?
Pay-Walls suck #
Look, it’s not that I don’t think journalists shouldn’t be paid. They should be. It’s just that having everything behind a paywall blows. There’s not any fun solution to this. Ads suck too. Nobody wants a web full of micro-transactions, and the idea of news sites mining crypto while I read bothers me too. So, let’s just ignore the news sites for a second, and instead, focus on the much more offensive situation: academia and scholarly articles (not that they’re all good to begin with (YouTube, DefCon 26))
It’s no secret that access to academic articles is fucking expensive. JSTOR alone is $200 a year for only 85% of the content, some individual articles are well above $20 to read despite a huge portion of it being publicly funded in the first place, yet somehow these sites wonder why so many sites are turning to Sci-Hub.
You Pay to Read Research You Fund. That’s Ludicrous (WIRED)
But it’s so much worse than that. Tons of information services are subscription based. So, the costs add up way worse. While it may seem like a bit of a stretch, I think it’s pretty reasonable to call Netflix, Hulu, etc. all information sources as they often host documentaries. Yet, if we look at The Cost of Every Streaming Service Per Month (TheStreet), and assume just the most popular ones, so Netflix, Prime Video, and Hulu, it’s already at $418 a year. Is it really any wonder why people are piracy again? Even if you subscribe to the theory that Piracy is a distribution problem and not a price problem, the pay walls are still the problem, as each service has it’s own incentive to hoard as much exclusive content as possible and make their platform better than others for the price. This means that each platform runs on it’s own standards and cross-compatibility is a real PITA. There are now websites and apps that specialize in just telling you which streaming service has what. Like what in the fresh fuck.
As an aside, if you want to get around paywalls you can use Switch your user agent to Googlebot, and that will usually immediately let you through.
Authentication and Authorization Suck #
Authentication is the sign in- the verifying you are who you say you are
Authorization is what the user and service can do, or what ‘permissions’ you grant the service and what you’re allowed to do on the service.
Authentication: #
I’ll bet cold, hard fictional cash that you’ve put off turning on two factor for a service you don’t give two shits about.
I’ll double my fictional money to bet that you have a junk password you use by default everywhere you don’t give a shit.
Hell, I’ll go all in betting on saying you’ve authenticated with quite a few services by just using the
button, though possibly only because it was the only way to login to that service at all.
Unfortunately, all of the above are probably not the best decisions.
The top two points combined mean someone can find your password in previous security breaches (haveibeenpwned), and then just login in, easy as that.
Using a social media login means that if you ever lose access to that account, either because Facebook or Google or Twitter or whatever decide to ban you or because you manage to forget you ‘master’ password and lock yourself out, you’ll be locked out of everything you logged into those services with. Not to mention if someone manages to break into your Facebook or Goggle or Twitter or whatever they’ll be able to login to any of those services too.
And look, I’m guilty of all of the above too. Sure, a password manager helps with this, but that’s still annoying too as sometimes you just need to quickly sign in on a device for a few minutes. As of right now there’s just no good solutions that are secure, easy to use everywhere, and fine gained enough to let the user give permissions as they want, and not give extra permissions they don’t want to.
Alright, so just follow the normal advice and use long passwords?

Yeah. No. Well sorta. Okay, let me explain. Yes, you should use long passwords for exactly the reason this comic explains. But really, we need to stop using passwords outright. They just sorta suck.
Instead, we should go to Single Sign-On, like the above “Login with Social Media” example, but the user should be able to trust and change the identity provider with ease, to avoid the ‘Facebook banned me’ issue.
The real shitty part is a lot of services already support something like this, letting you setup sign in with Single Sign-On via your own identity server, but it’s usually limited to enterprise users.
That said, you can self host Single Sign-On (like the way ‘Sign in With Google’ works), keycloak, Dex, Gluu are options for doing this. It’s just that basically no online services will let you use your self hosted service without an enterprise account.
So, for now, users get fucked. There’s really not any good options.
That said, some things have gotten better, Webauthn provides a much better way to authenticate with many services, including some that can provide Single Sign-On identities, often via those little USB keys which are hugely better than the typical user name and password paradigm.
If you really want advice on what to use for your personal, daily password storage needs I think keepassxc is probably the best option at the moment, though it’s still a tad awkward.
For advice on security and privacy see the Security & Exploitation and Privacy pages.
Authorization: #

Character owned by Vega, art by Shade
Put simply, we need easier to use, fine grain authorization settings that can’t be bypassed. I should be able to tell a program, website, or app that I don’t want to give it my location, and then, if it asks anyway it should be fed garbage. Refusal should also not stop access to that service(1). Similarly for storage, microphone, contacts, etc.
Newer versions of Android actually do this really well, including the ability to only grant those permissions for that session. This is amazing. It’s not perfect, far from it. Like, Bluetooth requires location permissions and, unless you’re on a rooted phone, there are some permissions the user can’t even give. That’s a load of shit, but I’ll come back to that.
Content Linkage sorta sucks #
Archive.org backup of the above tweetSearch is the biggest scam in UI now. It almost never works. How do you find stuff that is not in your top 10 results of mini snippets? We need more explorative interfaces taking advantage of context and association. pic.twitter.com/RC1BEekf3X
— Marcin Ignac (@marcinignac) June 4, 2021
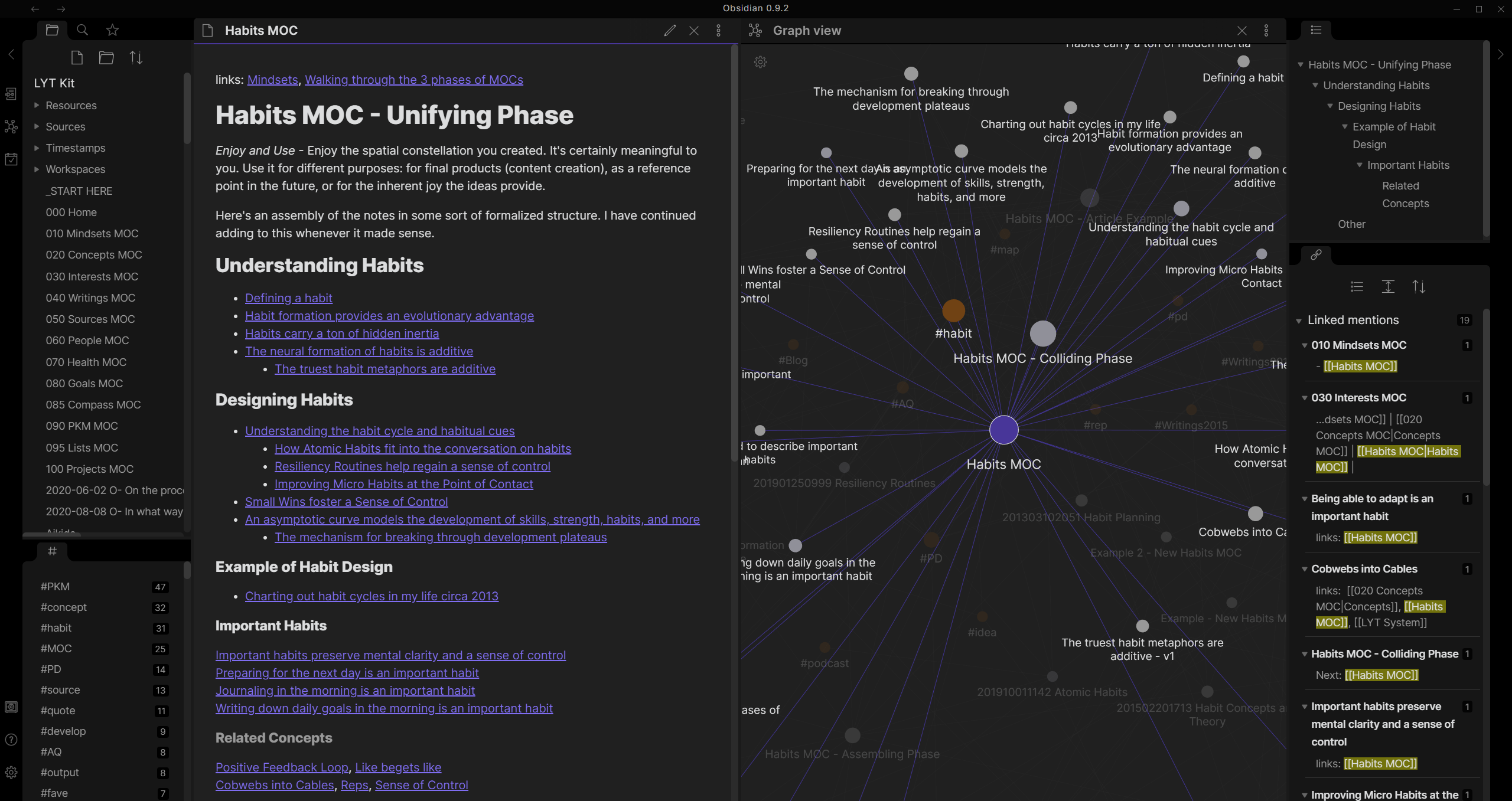
Screenshot from the homepage of Obsidian.md
The digital world doesn’t have to be lonely pages indexed like a book, why are we treating it as such? Today each page can point to any other page in a beautiful web of interconnected information, where each topic has lines of association spanning such that no two pages are unconnected. Wikipedia sort of has the simplest form of this, but what if we had systems so capable of automatic understanding - not just tagging - of information that any new info could propagate though that web naturally. Social linkage to people in the same graph, even if anonymous, could help connect people that together, due to their very specific knowledge, drive man kind further. I should clarify to, I literally mean a web/graph, possibly in 3D, relating and indexing information, possibly like these 3D views of Wikipedia: (though the data should probably be served ‘raw’ so that other presentation methods can be developed, as this definitely wouldn’t be ideal for actually reading the content)

WikiGalaxy: Explore Wikipedia in 3D (wikiverse.io is very similar and worth checking out too)

It seems weird to think about an algebra book where it suddenly references multidimensional calculus, but this is exactly what I’m implying. In my education there was uncountable times I had to learn something because ‘it will be used later’ with no explanation as to how or why. Linking back up the tree allows for information traversal in both directions, eliminating this problem.
Presentation of Information Sucks #
This section is about how we view information, the presentation of words on a page, graphs, and information in general. To start, I want to look at something a little bit different.
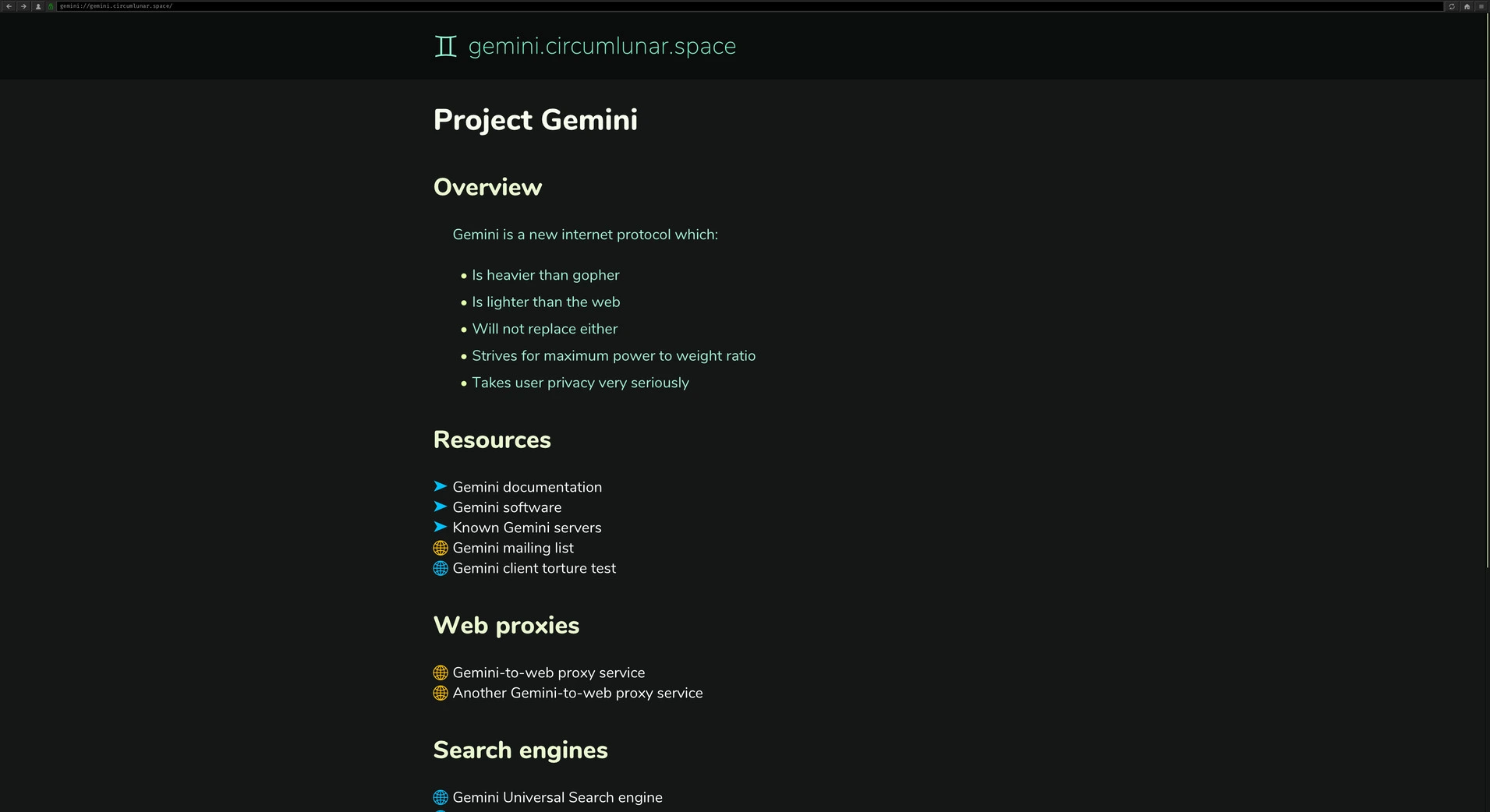
This is the home page for a project called Gemini, which is a sort of alternative internet, but, wait, hang on…
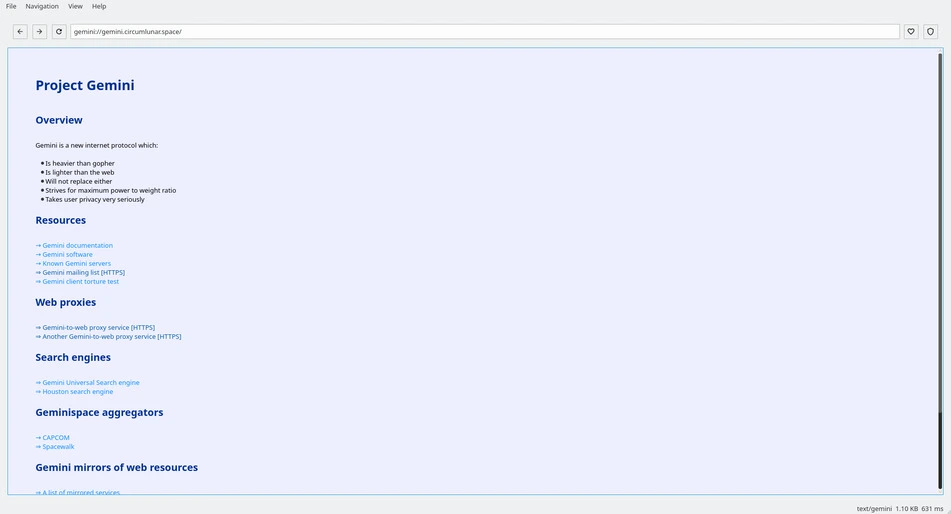
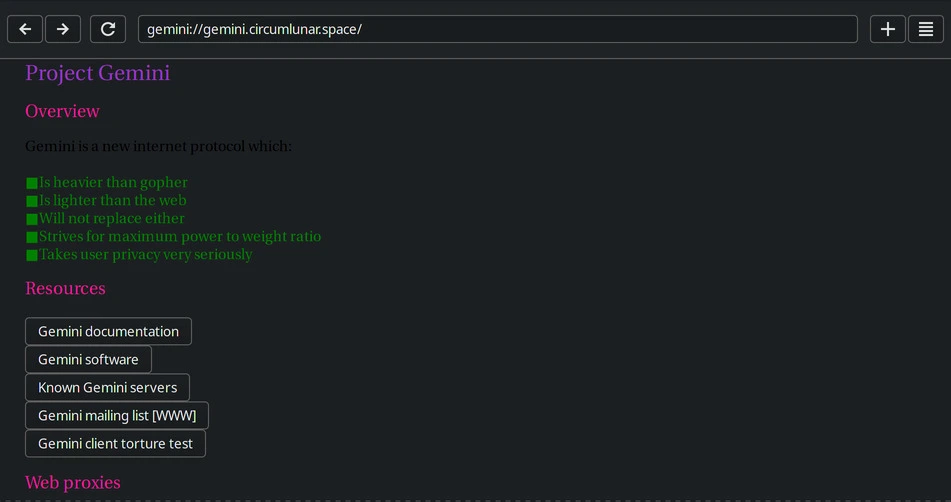
These are both that same page, loaded in different browsers. Why do they look different?
Well, Gemini does something you may thing strange: It let’s the browser (client) handle the look of the page. It only serves the raw text. That’s it. That’s all you get.
Now, I do not think this is a good idea for the general web. But, I do think as an idea, it can give us some valuable insights.
Put a pin in it for now though, let me jump ahead into Dark Patterns:
‘Dark Patterns’ #
A dark pattern is “a user interface that has been carefully crafted to trick users into doing things, such as buying overpriced insurance with their purchase or signing up for recurring bills”
That’s the definition from Wikipedia anyway. I think it’s a bit better put as “Dark Patterns are what happens when UI designers are a bag of dicks”
This Site has a lot of really good info on Dark Patters, and I recommend heading over there and then coming back over here.
Oh, cool, you’re back.
The biggest dark pattern that drives me nuts is a bit of what that site calls ‘Confirm Shaming’ and a bit of ‘Misdirection’, I’m talking about sites that do this
where the design is actively pursing an agenda. But it's not just those. Even ones that look semi reasonable can still be annoying if they don't include the action directly. The affirmative action should be stated on the button that triggers it and both actions given equal weight to the user.
for example
Note here by Action I literally mean to include the verb. Delete. Replace. Print. Etc. Yes or No is not good enough.
With destructive or irreversible actions, such as deletion (not recycling), given a confirmation dialogue, and if particularly important, a dialogue that require meaningful user input, like this prompt when deleting a repo on GitHub
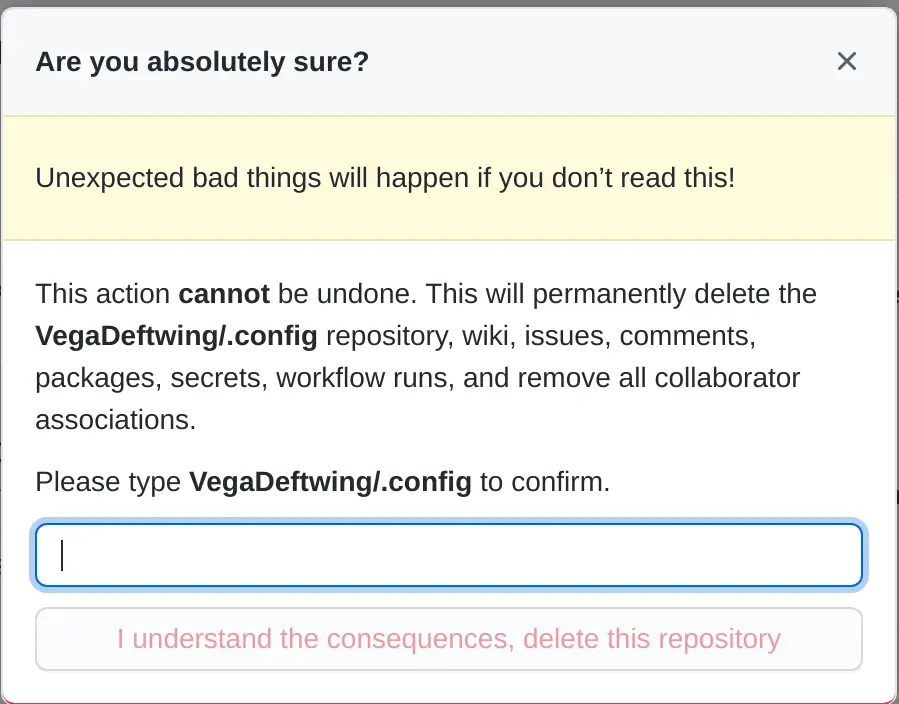
Alright, so back to Gemini: Making more things like it wouldn’t totally solve this problem, designers could still totally chose to make the text confirm shame, but by letting more elements be controlled by the user (or their browser), we could at least do a little bit better by letting that ensure options to confirm or deny are given equal weight and that they are colored appropriately.
It’s not like this system couldn’t be abused still of course, and there will always be a balance between the user trusting the service and it’s UI and the beauty of that UI, but I think we could stand to go a bit in the direction of Gemini.
Misleading Information #
Global warming relies on the theory that we are destroying ecosystems. There is no evidence that we could destroy ecosystems.
- Rush Limbaugh, recipient of the Medal Of Freedom.
Yes. Misinformation online is a royal fucking shit show. There’s no way to possibly preserve total free speech, not that free speech is always perfect, and also have a system that doesn’t spread misinformation to the extent that people stop vaccinating their kids or thinking that COVID is a hoax. I’m not trying to address that problem. If I could, I would. But I honestly think that’s a genie we can’t really put back in the bottle now.
Instead, I think we could do some things to make it a bit harder to spread stupid, false information by making it a bit harder to present data in misleading ways. Sure, the data itself may still be bad, but, we can make an attempt to increase transparency and display data accurately. How? Well, first, go have a look at some comically bad graphs (Statistics How To).
A lot of these come down to graphs that purposefully play with axis or do other bullshit with the express intent of tricking you.
So, fuck their formatting. We should do it the Gemini way: Let the client handle the data display, and make the graphs interactive. If it’s a two bar chart with one bar at 54.5% and one bar at 55.0%, that should be what the user sees first and only then can zoom in.
This is already easy enough to do with something like https://d3js.org/, but it would need to be on the client side, and the server would just have to send the raw data + a preferred way to render it (bar chart or whatever), otherwise the problem is still there. Over time standards could grow to support more display formats. This would have the side effect of making it easier to author data and make web pages in the first place.
This also makes it easier to compare data sets, as now the client actually has access to the source data, or at least the data that drew the graph.
This practice could be incentivized too, as news, shopping, and review sites that use it could do so as a way to build trust with their users, and, probably more importantly for adoption, shit on their competitors that don’t do the same.
For those that still don’t, it might be possible to spin up a system with some machine learning to extract data from graphs in static images, and then re-display them as dynamic content.
This may not ensure the data is good, but at least it makes progress in increasing how we can trust data to some extent.
This could have extra uses too. Having something that could take two 2D graphs with a common axis and turn it into one 3d graph would be incredible, particularly if that data could come from multiple sources across multiple domains. Combine this with the ability to change the type of graph and this could help expose otherwise non obvious trends. After all, some of the best discoveries come from random people making cross disciplinary connections.
Beyond that, content moderation needs improvements too - I don’t even mean fake news or porn here (Though we could stand to have better nsfw tagging on most social media). I mean the bullshit reviews on Amazon or the fake products when shopping online (mostly fake electronics). If those services are going to be allowed to make stupid amounts of money, they should be required to do at least a tiny bit of consumer protection. Hell, Amazon was even selling Negative Ion/Anti-5g Products Are Actually RADIOACTIVE (The Thought Emporium, YouTube).
Information Overload #
Yes, I see the irony in a post this long.

Bobby Mikul, Times Square :CC0 – Source
Information overload is increasingly becoming a problem. As more and more information is accessible at our fingertips and more advertisements have the opportunity to be beamed via any one of a number of surrounding screens directly into our retinas we need a way to filter it down to levels the human brain can cope with and digest.
This is a complicated subject, on one hand, it’s amazing to have an infinite wealth of information. On the other, an ever growing amount of that information is shit and irreverent, and eats away at our very limited mental processing time for the day, we can only ingest and actively pay attention to or throw out so much information, and when much of the information we seek to avoid (ads) are actively doing everything in their power to demand attention from our brains, be it with sex appeal, bright colors, or even humor, it’s an uphill battle. So what can we do? Well, a good start would be to legally limit advertising to be less distracting from normal content and make the advertising more easily distinguishable from the real content. But I don’t think that’s enough. I think if we’re going to make systems that have machine learning to get better and better at sucking our time we need to put in just as much effort to making design that promotes health and consumption in moderation.
An example of this is Netflix’s ‘Are you still watching?’ while this was implemented on their end to prevent unnecessary usage of data, it has the side effect of letting a user know they’ve been on the couch longer than should probably be advised. I’m not advocating for interruptions at every corner, just affirmative action by the user before bombardment with data. I do think as much data as possible should be linked to or aggregated, but force me to see more than what I request plus some surface level information. For something like YouTube this might mean playing a playlist is fine, but don’t start playing another ‘related’ video when that list is over.
Beyond that, keeping the design minimal but powerful. I think markdown is a great example of this. Users aren’t as dumb as people seem to think, we can, and do, learn the ways to make interaction with the things we use daily faster, so make the ‘speed limit’ as fast as it can be while lowering the need for menu diving and learning to do complex actions. Putting a frequently used option into a menu that needs to be clicked at all is much slower than assigning it a keyboard shortcut.
But, okay, back to information overload: The biggest problem is still that there’s just too much. I don’t really think there is a solution, maybe Banning Outdoor Ads like Brazil’s Largest City Did, would be a start. Maybe requiring that the Terms of Service for any service a user signs up to be a limited length and actually commendable would help. But I just don’t know. I think the world has just simply progressed to a point where FOMO has gotten to a point where missing out is just a fact of life as 500 hours of content are uploaded to YouTube every minute.
What I do know is that trusting the YouTube or Facebook or Twitter algorithm to decide the content I see is incredibly dangerous, but that the alternative is overwhelming.
Meanwhile, legislation that has been passed to try to fix some of this often results in other issues, like all the ‘Can we give you cookies?’ prompts on websites: Why The Web Is Such A Mess (Youtube - Tom Scott)
Backup of thread on Archive.orgImagine: drag to select text, pinch to summarize, vertical unpinch to generate alternatives, *inspiration*, record new sentence to replace the old one
— Azlen Elza (@azlenelza) November 25, 2020
And voilà, you've explored multiple directions on the landscape of meaning and rewrote a sentence in just a few moments
4/4 🧵 pic.twitter.com/LlcmcY3kpw
Updates after Initial Draw #
Fuck your shit. Compute first, then display.
This may be the most irritating thing I encounter with modern computers. Our brains and bodies, as much as we may wish them to, don’t respond to stimuli right away. So, when I search for something, go to click something, and then while I’m moving the mouse to click the screen updates and a different link or icon is now in the spot I meant to click it’s really fucking annoying.
Window’s built in search, especially with web results on, is a huge offender on this but Google and other search engines do it too.
It’s not just search either, I’m sure everyone has encountered this in various places.
All you have to do is not change shit until you’re done computing the answer, and then only change it once. This is about as simple as it gets and it avoids magical re-arranging menus that make everyone lose their shit.
Everything needs to be more damn responsive #
Fuck your 𝒻𝒶𝓃𝒸𝓎 animations. I love eye candy, and a little bit is fine, but I shouldn’t have to wait as a menu slowly drops down with some pretty animation. If I’ve used that menu before I probably already know where I want to click, and now because I expect to be able to do so instantly I just clicked whatever is behind it. Fuck that. If the animation is masking some load time, sure, but as soon as it is loaded, quit it, and show the damn content. If the animation is necessary to avoid suddenly flipping from black to white and blinding users, again, I get it. But it doesn’t need to take more than 100ms.
Advertising #
If I have to spend more than a fraction of a second to process what is being shown to me is an ad, it should be fucking illegal. If you want to put ads mixed into the content, then it should be required to be a lot of a lot more visually obvious.
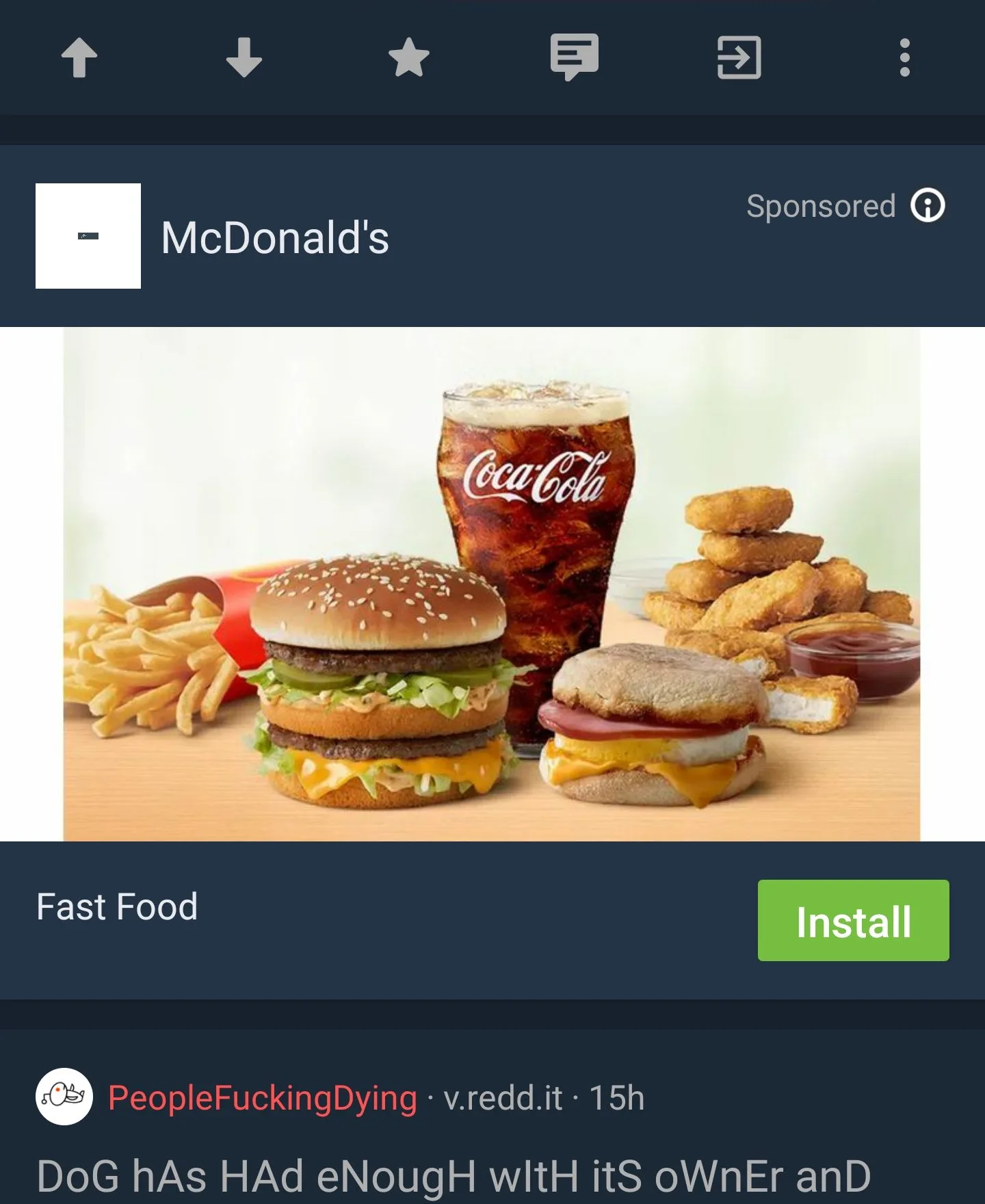
Original:
Edited:
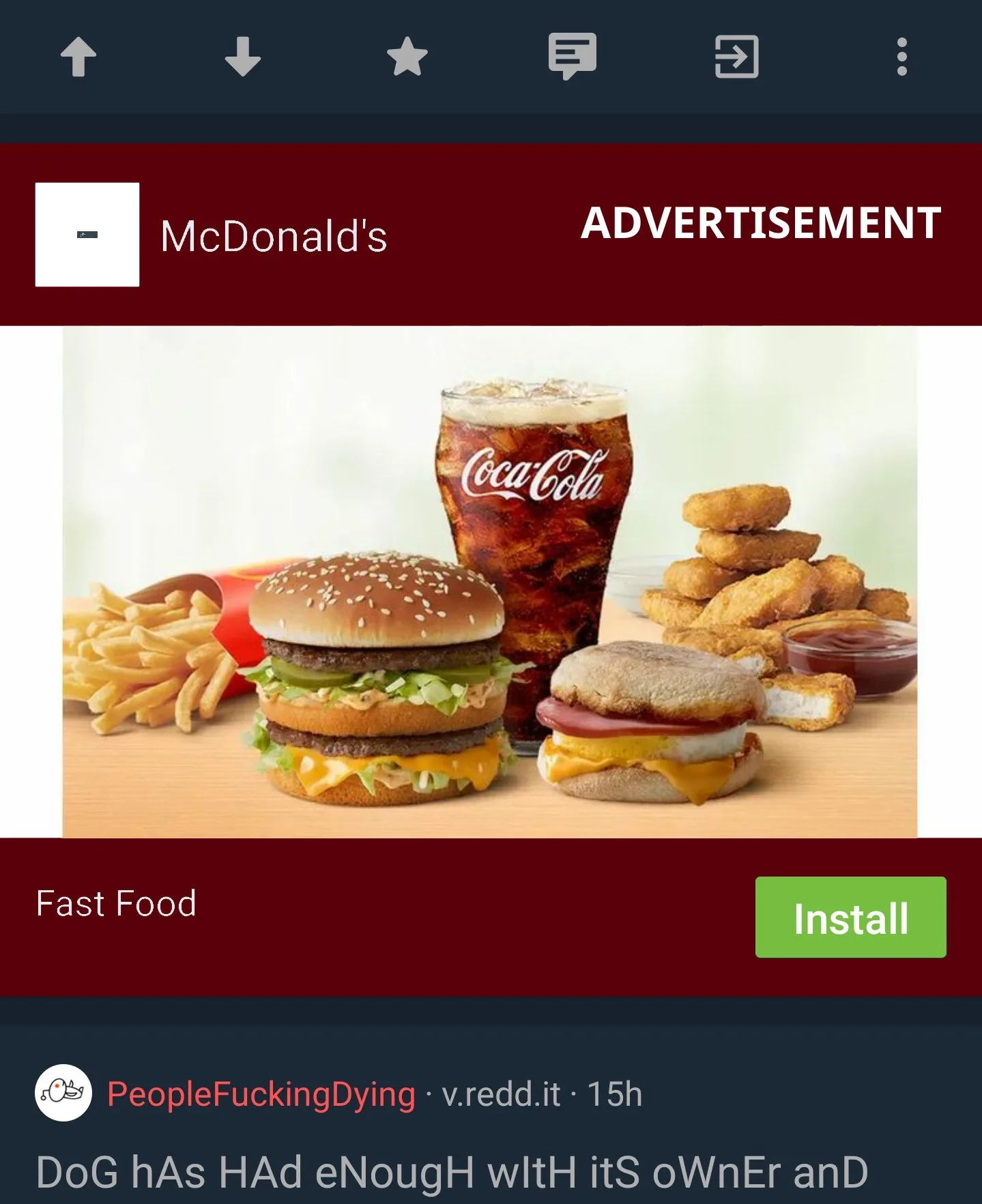
Here the original at least has some color differentiation (Using the Boost app to view Reddit) but on the official Twitter client I actually have to stop and look to avoid accidentally clicking an ad link. That’s some bull shit.
Yunno what else is bullshit? The fact that all of these ads are ‘personalized’ to the point that collecting crazy amounts of information on individuals is expected and almost inevitable online, even with a pile of tracking blocking extensions and a DNS blackhole like pi-hole. This could, and should, be a rant of it’s own (and is, again, see the Privacy page) Being spied on by our own devices is 100% not okay and it’s one of the biggest reasons that they way we interact with computers sucks.
Storing Information Sucks #
Storing your data blows. Users have to contend with backups, backups for you backups, bitrot, file size vs compression, what file system to use, how to make backups actually convenient, mirroring information between systems with limited bandwidth, etc. But to start somewhere let’s look at archival:
Archival #
Digital archival on ‘cold storage’ sucks. For one, that cold storage is often either a PITA to attach in the first place, Usually using either using a slow USB interface, an expensive and far-from-universal thunderbolt one, or, if you want to go very bulk storage, requiring a specialized PCIe card which is meant for servers which brings along it’s own pile of issues.
But even once you have everything attached, most of the time backups are pain to run. You can always do the lazy copy-and-replace-existing method, but that’s painfully slow as it has to check all the current files instead of just doing the logical thing and comparing two indexes, but, of course, most file systems don’t support this index based method. Sure, there’s software to add it, like Bvckup, but most that I can find is paid or not something I would trust. Right now, the best thing I can find is using rsync, as I have a script with a bunch of lines like
|
|
and, yeah, that works, but it requires a reasonable degree of tech-savvy-ness
Using Git (or GitAnnex) is of course an option, but that has a higher barrier to entry to learn than seems reasonable. At the same time having actual file versioning needs to be a thing, something better than having untitled.docx, untitled.docx,untitled3final.docx, and untitled3.5.finaler.docx, even if it is still storing the file in full (though hopefully compressed) behind the scenes.
But, on the note of indexes, why are tools to provide a disk-offline index not better. From what I can find, catcli and Virtual Volumes View are the main two options, and both are bit out of the way to use, compared to just having it be natively in the file browser.
Phone ↔ PC is the fucking worst. #
MTP needs to die a very painful death. USB Mass Storage, that is, devices that show up the same way a flash drive does, are infinitely easier to work with. On Android, with large folders, I’ve found adbfs, a tool that lets you do file transfer over Android Debugging Bridge, to be much better than MTP, but, really? No ’normal’ user should be expected to use that. Hell, a lot of people are just uploading files to the cloud and then downloading them on the target device because it’s easier. There’s also a growing number of apps that let users to transfers over wifi by hosting an Samba server on the phone, but why would something wireless be better? It’s absolutely crazy that things have gotten this bad.
Also, while I’m bitching, can we please stop removing the SD card slot ( and headphone jack )from phones? I like being able to take my full music collection with me.
We’re using ancient formats #
Look, jpeg and png are perfectly fine formats. For 2000. It’s 2022. HEIF (or BPG) really should be standard. Instead, it’s a motherfucker because M$ is too damn cheap to include the HEVC extensions which it relies on it without either having the user pay $0.99 (or claiming to be the OEM) because a collection of jackasses have it patented so hard and require licensing fees such that it may as well not exist. HEIF/HEIC or BPG I think have a good chance because of the preexisting hardware acceleration, but other formats like hific, which uses GANs to do compression, look promising too.
As a note about why I wrote about HEIF/C in particular, most phones are capable of storing images in this format now, and IPhones do by default, which is a real PITA if an apple user emails these pictures to a Windows user.
Of course the same applies in other formats. .flac is replacing .wav for high end audio, but why not Direct Stream Digital (DSD)?
- All the best formats are a pain in the ass
- format shifting sucks, opening them sucks, patents suck
- People use some really, really shit formats
- A lot of formats are needlessly complicated and not human or computer readable to anyone but the software vendor
Bit rot? #

Data on the internet gets compressed, saved, recompressed, resaved, upscaled, re-colored, and deep-fried pretty quickly.
This combined with more traditional bit rot, where errors result in flipped bits, is a massive PITA.
Sure, tools like Waifu-2x help with the first problem, but using AI-up scaling to fix the loss of data isn’t ideal. For actual bit rot, tools exist to detect bit errors in most formats and you could always use a better file system that does check summing, but both of these require more technical skill than most people have.
While not exactly related, data accumulation and near-duplication (think having two pictures with one having just a 2px cropped off the top) is a big problem. Trying to sort though a mounting of images, text, or audio files can be nearly impossible if put off for too long, making good digital hygiene a must despite the fact that nobody ever tells anybody how to have good digital hygiene in the first place. (don’t ask me!)
AI tools to tag and identify images and audio help, but those tools are still limited and often only work well on uncompressed data, so no .jpgs or .mp3s for you. Plus, a lot of them upload your data to get processed (privacy concerns) or just don’t work on some data (good look tagging all the pictures in your homework folder)
With all of this combined, keeping your files in order, not corrupted, and not having duplicates becomes a growing issue.
Storage Hardware and File systems suck. #
The hardware issue is mostly a side effect of trying to market technical differences to people who ultimately just want a place to drop their files. A normal user shouldn’t have to know what all the various specs of a HDD or SSD mean to know what to buy.
That said, holy shit do manufactures suck at this. Everything from Western Digital redefining ‘RPM’ to Western Digital uses SMR on NAS drives, DRAM-less SSDs and Bait-and-switch in regards to SSD performance.
SMR, or Shielded Magnetic Recording, has a few issues that make it problematic for Network Attached Storage (NAS) systems using multiple disks, particularly if the NAS is running ZFS, a common file system made exactly for this use case. So Western Digital doing this was well and truly a massive fucking problem for people needing to store a lot of data.
But the issues go beyond that. While a bit controversial, I think literally any modern filesystem (BTRFS, ZFS, or even EXT4) is much better than the mess that is NTFS, yet, Microsoft only officially supports NTFS, FAT(/32), and ReFS- all of which sorta suck.
There is no fucking reason everyone - Microsoft, Apple, Linux, etc. - can’t fucking agree on something and avoid the massive fustercluck that is using FAT32, a filesystem that can only store files up to 4GB, as the only common system that “just works”.
Note, you can use BTRFS on Windows, using 3rd party tools. This seems to be stable enough and has some real advantages for dual-booters. Technically, the same is true of EXT2/3/4 too, but I don’t trust it to not eat my data.
Ideally, we’d be using Logical Volume Managment so that the entire filesystem can have snap shots, partitions could be resized, or use multiple physical disks
I also don’t get how in 2022, some systems are still booting off of spinning rust? Hell, why are we really using it at all. Yes, I know the price per GB is much lower, but we’re talking about something that is so sensitive to vibration that Shouting In The Datacenter is a problem. This is extra dumb when you consider a lot of computers or game consoles will be right next to speakers and subwoffers. Every time I pickup a laptop with an HDD and I can feel the inertia of the disk it makes me cringe.
Cloud Storage is a terrible idea #
To keep the core of this issue brief: The cloud is just someone else’s computer. You can never be certain of what they’ll do to your data.
You can’t be sure they won’t have some random DMCA complaint take something down.
You can’t be sure they won’t suddenly increase price and essentially hold continued access to your data at ransom
You can’t be sure they won’t mine your data for targeted advertising
You can’t be sure your data won’t accidentally be public because of bad security.
Just don't put your data in the cloud.

Character owned by Vega, art by Talon Creations and Vega
That said, I will admit two valid uses:
- Collaborative Editing. GSuite is actually pretty cool.
- Backup but only if the service is only backup and you already have at least an on site backup. For example, I think Backblaze is actually a pretty neat service and it seems like they do things reasonably. The ship you a hard drive option here is what makes it make sense to me. Note, I’ve never actually used Backblaze.
But 1. still has issues, especially if the format the collaborative documents are saved as are only valid on that cloud platform. Think like .docx for Word, but what does GSuite use? Can you be sure it’ll work offline?
I’d also like to mention the idea of distributed computation here as well, as It can be used for both the storage of and computation on data. I think that having a true distributed system in place, one where all users contribute compute and storage for it’s use, makes sense. The obvious ask is to get it to be self sufficient. This brings up the idea of balanced usage to contribution, I think the easiest solution is to simply use a system of computational debt tied to each user account. If the user is creating more computational debt than the average debt the system can sustain then that user should be handicapped in bandwidth accordingly. This does sort of bring us full circle in ‘can I just trade debt with someone, or sell them my computational time’ such that we’re back to crypto based services again though, and I really don’t like this idea for two reasons:
- This system needs real time computation and bandwidth, and these vary in value just like how electricity peak hours cost more.
- This incentives simply paying for compute time instead of actually contributing computational power to the network like it actually needs, which in turns creates an incentive for people to do this at scale annnndd look at that we’re back to centralization.
The biggest problem with this is that home Internet users very rarely have symmetric connections, so people would probably be very pissed off if their download speed were suddenly tied to their upload speed. This could be offset by building up credit, as previously mentioned, but that has the issues, as previously mentioned. I suppose there could simply be a credit cap, but setting that would be exceedingly awkward as a logical number to use would vary by user and how they use the system.
I do hope that someone has a better idea than me for the future of distributed computation, because I really can’t see any good solutions despite wanting it to be part of the future.
I’d also be remiss if I didn’t mention Boinc, a tool you can use to donate unused computational resources from when your computer would be otherwise idle to good causes such as Searching for Extraterestial Life or Folding protiens to look for cures to various diseases.
Unfortunately, in response to criticisms, like this one, of cloud storage a lot of providers of “Personal Cloud” devices have cropped up. Though, headlines like “I’m totally screwed.” WD My Book Live users wake up to find their data deleted and If you have a QNAP NAS, stop what you’re doing right now and install latest updates. Do it before Qlocker gets you might go to show why that’s also a pretty fucking stupid idea.
Transferring Information Sucks #
I mostly mean networking, but things like flash drives too.The Internet Sucks #
Well, okay, the internet is honestly fucking awesome. But some of it is designed horribly and some of it is nowhere near as good as it could be because of users making stupid choices.
To start with, let’s look at how horribly shit was designed. As a start, I recommend reading IPv6 Is a Total Nightmare — This is Why by Teknikal, it explains the issues with both IPv4 and IPv6 beautifully. There are other issues with the web, like the fact that neither DNS or IP were designed to be encrypted (and so private) by default, so instead we’ve had to patch on fixes like https. Of course, there network security problems are found regularly, such as Nat Slipstreaming, a nasty issue that made the rounds recently.
There are also issues of access. In the US at least, most places are part of an ISP regional monopoly. Often they’ll argue that you do have options, such as satellite internet. However, this is complete and total bull shit. You do technically have the option, sure, but this option is slow, usually has data caps, and just generally sucks. If you’re in a rural area, you’re lucky if the copper in the ground is still good enough to get you something fast enough to watch a YouTube video. Then, on top of all this BS, the ISPs regularly get caught for doing shit to your traffic, whether it be injecting ads, terminating connections early, blocking services (often torrenting), not letting you forward ports, etc. Oh, and then they try to charge you for a modem you don’t even have- thankfully that was just made illegal.
TLDR: ISPs are evil.
Centralization Sucks #
At the time of writing, a lot of decentralized services are hopping on the cryptocurrency train. This is really fucking stupid. So, while projects like Lbry, Dat, IPFS, and the Beaker Browser are cool, until the space cools down a bit and stops thinking Crypto is a good idea I’d recommenced proceeding with extreme caution.
Most services on the Internet are Centralized. When you get on Facebook, you’re connecting to Facebook’s servers. YouTube? YouTube’s servers. And so on.
What if, instead, when you watched a video it downloaded it to your computer (at least for a little while) and then, when the next person wanted to watch it they got it from you. As more people watch a video, the number of people who have it grows, and so it’s faster for the next person to get it. This is a system that naturally scales. It’s also resistant to censorship (which is both good and bad). A slight variation on this is the idea behind PeerTube. Similarly, there’s mastodon as an alternative to Twitter.
But we can do better. With tools like ipfs or cjdns we can replace the entire back-end, the internet itself, with something that is inherently decentralized and peer-to-peer.
↑ Note, this video has a part 2: Decentralize 02 / VoluntaryNet: The Digital Public Square
Transferring Your Profile Sucks #
Say you want to move off of Twitter and go to Mastodon, how do you do that? Well, there are options. You can run a bridge account and have toots from Mastodon get automatically posted to Twitter and just leave a pinned tweet saying you’ll only reply over on Mastodon. But, wouldn’t it be better if you could import all of your tweet history?
What if you get a new computer, wouldn’t it be nice if setting it up was as easy as just copying over a settings file that has everything you want, all your programs, configurations, accounts logged in, etc? Sure, you can get close by using a few “super accounts” like signing into Chrome, Steam, etc. but then your both trusting other services with your passwords and all your data.
I think this comment points to a better idea:
For this, I think Solid, a project by Sir. Tim Berners-Lee, the guy behind the World Wide Web, is a decent implementation of this if it were to gain enough traction to actually be used.
Solid’s central focus is to enable the discovery and sharing of information in a way that preserves privacy. A user stores personal data in “pods”, personal online data stores, hosted wherever the user desires. Applications that are authenticated by Solid are allowed to request data if the user has given the application permission.
But the point I’m trying to convey is that right now setting up a new device or logging into a service sorta blows. The user profile needs to be secure, user-owned, and decentralized. For those that know Linux, it’s what making your ~/.config folder into a git repo should be like.
Speaking of “Your Profile”… #
While, yes, advertisers collect a bunch of information about you to advertise to you in a profile that you can’t control and that sucks, others have spoken about that extensively, probably most entertaining for this Data Brokers: Last Week Tonight with John Oliver. But, most people also have some intentionally public online presence, where they have some information they’ve decided they want people to be able to find. The comfort with this varies from person to person, but for many it may include age, birthday, gender, name, place of work, and a few hobbies.
You’d think this would be easy enough to get right.
It’s not.
First of all, let’s pick on gender selection.
If you make a website or app and do this:
You can go fuck yourself. “Trans” is not a gender. If someone is trans, they are now identifying as a different gender than the one assigned at birth. If you really must know, this can be a box, but, it’s also probably none of your fucking business. What you should probably have is something either asking for preferred pronouns, or, if you absofuckinglutly must have their gender and know if they’re trans (which, uh, no, you probably don’t.) then proceed with caution. Otherwise you may end up in one of @Foone’s many Twitter Threads making fun of bad UI choices.
Even with names, this is easy to fuck up. Like Google+ (now dead) wanting only “real names” which is a privacy disaster and has real issues for some people with uncommon or long names, and it’s even worse for those with either weird characters or no last name. (Different Cultures are a thing, remember.)
Basically, anticipate there being someone, somewhere that doesn’t fit nicely into your design. Someone will have a name with a substring that contains a curse word when interpreted in a different language. An intersex person may sign up for your website and be neither Male or Female while also not being trans or gender fluid or anything else you anticipated.
As a user, this means we really, really need to be able to fully control our profiles. Let people enter their own preferred pronouns, names, etc. Don’t make it a checkbox.
Local Backups By Default #
Most web pages are reasonably small, especially if you ignore java script crap. Why do browsers not just backup all web pages we go to (on desktops and laptops where storage is a non-issue) ? This would provide the benefit of being able to do a local text search of everything browsed recently as well as backups in case the page goes offline or moves.
There are tools that do this already (like Archivebox) which can be automated but it’s still not user friendly to normies. There are also sites like Wayback Machine and Perma.cc that will save copies of websites for you and provide a link that should always work, even if the website goes down or the address changes, but again, this is a bit of a pain. It also can lead to copyright issues for these services.
Why can’t you easily search all of the text you read on any screen (desktop + mobile) over the past day? It’s strange how much obvious, low-hanging fruit of this form still exists.
- Patrick Collison (Stripe CEO)
Physical Interaction #
I also think the boundaries of physical and digital should be more blurred. I’d love if I could set a book on my desk and search though it for an idea or concept by mere image recognition of the cover, or if it’s an unknown book at least being able to digest any pages shown to it explicitly. Say a section was highlighted? It would be great if that were automatically added to a personal journal file of sorts for future reference, especially if related data were automatically associated with online sources, or links made to people who are interested in similar subjects.
The Screenless Office (Screenl.es) and
![]() Dynamic Land
both show this idea pretty well.
Dynamic Land
both show this idea pretty well.
Creating New Information Sucks #
Or, People Will Only Make Stuff That Is As Good As The Tools They Have
Note the “Will” and not “Can”. A very talented musician can make a shovel sound good, a talented photographer doesn’t need a good camera. But in general that’s setting the required bar of talent - and therefore time - higher. The better and more efficient our tools are, the better content people can make without putting in more time than they’re willing to.
A better camera won’t make you a photographer, but it might be the difference between unusable pictures and a saved memory for someone with less skill.
I think I’ve generally made the case that our tools suck so far, but here’s where I think things can get really interesting. I’ll break this up into multiple problems:
We Need Faster Input #
WYSIWYG (pronounced wizzy-wig) or What You See Is What You Get editors (usually for text and images) are those that do their best to make sure that what you see in the software directly relates to what you’d get if you printed it out or sent it to someone else - Like Microsoft Word. Unfortunately, it’s often true that WYSINWYW What You See Is Not What You Want. That is, controlling software like Word is a massive pain in the ass. So While WYSIWYG sounds great in theory, it’s often hard to use, a menu-dive hell, and is slow compared to something more limited like Markdown. Markdown is what this website uses, in a nut shell
You write text like this
|
|
And it turns into this
Title #
normal text, something in bold,
and a title in itilics.
- a bulleted list item
- and another
some code
| and | a | little |
|---|---|---|
| table | with | some |
| content | for | demonstration |
a quote
The advantage here being that once you’ve memorized the special characters for formatting, they’re really, really fast to type. Plus, if you want to change the style of the content you can just change the way it’s rendered - for this website that’s defined with the CSS (the “style sheet” of a website) but in an exported document to PDF a given markdown editor probably has a dozen different themes to choose from.
The biggest problem with markdown is that you need to take that text with the special formatting characters and render it. This, historically, meant that you’d have a pane of text you write in and a different pane where you see what the final document should look like. This is confusing and eats all your screen space. Fortunately, tools like Typora, Marktext, and Obsidian.md all have the ability to render things in the same window as you type, making it feel totally natural.
But, alright, that’s a lot about editing text, what about for editing pictures? Making Videos?
Well, I think a large part of that comes down to having tools with AI assisted tools. If you can put in natural text saying “Perform red eye removal”, “blur the background”, or “add film grain” that’s already a huge leap forward, but with actual object recognition in the photo, it’s reasonable to expect we may be able to say something as specific as “remove the dog in the bottom left”. Plus, as full realistic image generation tools get better - see DALL·E 2 - “make this picture look like it was taken at night” may become something you can do.
Even for original digital art, there’s a lot that can be done, for example see PaintingLight which can automatically shade/light digital art.
For video, the same ideas apply. Some of this is already being done by https://runwayml.com (though their pricing is a bit high given it’s browser based).
We Need Tools that Scale With the User #
On one hand, I really hate baby sitting users that don’t want to learn how to use software - espically software they use every day - on the other, I know not everyone is capable of remembering how to use the deepest features of Word (or, have mercy, Blender) and often just want to do something quickly.
Right now, this problem is largely solved by just having a bunch of different products depending on what a user needs. Just need to quickly draw over an image to circle something? MS Paint will probably work fine. Want to do digital art? You probably want Krita. Photo Editing? Photoshop Affinity Photo will work well.
This isn’t great, in part because it means that work is being duplicated, but also because it means the UI for actions common to all three isn’t the same. We need software that can open, initially, with the bare basic features (The MS Paint equivilant) but can have things added and removed as needed, and profiles with different configurations saved.
This also comes with some responability on part of the developer to provide great documention, user extendability (Let users write their own plugins in Python!), and to have good in-software help. That last point is worth the hassle of development. Having the ability to hover over a button for a bit and it telling you what it does is much, much better than digging through docs to find it.
We Need Interopability #
Say you’re working in Krita making some digital art and want to load your file into Affinity Photo to use it’s lighting system on your art. Well, you can do this. One option would be to export the file from Krita as a final render, probably as a .PNG, trust that you wont find anything you won’t have to go back and change, and do what you need to do. Another option is to abuse the .PSD format (Photoshop Document) which is, uh, not a good format. This would preserve the layer structure which will allow for more advanced editing, but is clearly not great.
So, I’m just arguing for standardized file formats, right?

Character owned by Vega, art by Shade
Standardized file formats, where possible, do help. But I also realize why we don’t have them. Sometimes you want a new feature that just doesn’t have a place in the current format. If we wanted a generic format that worked everywhere, the format would effectively have to be able to include arbitary binaries in it to work on everything. So, uh, that doesn’t work.
Instead, what I’d like to see is software that does three things to work around this:
First, actions should, as much as possible, be non-destructive. This means they can always be reversed and or taken out of a chain of actions performed.
Second, software should assume that it does not have a lock on a file,
Third, actions taken in software should be a log of events to recrate the final product (caching expensive actions as possible), not the actual result.
If you combine these three things, it would mean that multiple programs could actively work on the same file at the same time. They just have to look through the shared log file and perform their actions in order according to the log.
Now, if you wanted to work on the same file in Krita and Affinity Photo, you could literally edit it simultaniously in both. Changes would just propogate for as much of the standard the two have in common. This works best if one program supports a sub-set of the other (as in, if Affinity supported everything Krita did, and more - but not Krita supporting some things Affinity doesn’t and Affinity supporting some things Krita doesn’t) but even if that isn’t the case, it’s reasonable to just document the places the overlapp fails and still see this as a win.
To be clear, I know this is a pretty utopian idea. It assumes that multiple organizations will actually standardize, that they can play nicely with interprocess comunniciation, and that people actually keep their software up to date to keep up with standards that will naturally evolve. Still, I think this is the way forward. Integartion and simultainous workflows in multiple programs just opens up so much possibility. Hell, if this was done there’s no reason two artists couldn’t work on the same piece simulatiously. Imiganie, two artists working on the same piece (though probably in different layers) able to work together.
I also know copyright and patents are an issue with this idea. Let me dream.We Need Tool Composition #
As an alternative to the file format clusterfuck, it may be better if programs themselves composed nicely. If you’re a unix nerd, you may see either of these two ideas as “The Unix Phillosophy”. Regardless, my point is that if each primary task someone wanted to do (writing, photo editing, text editing, etc.) had a good, base program different vendors - both free and commercial - could focus on providing extensions to it or making bridges to their own software and allowing for them to work together.
As a motivating example, say you want to write a fantasy book. You’ll want something for writing the actual text (duh.), something for mapping how characters know or are related to one another, a tool for making the outline, something for generating a world (land masses, religion, history, etc) and documenting it, etc.
Each of those tools could exist as independent software, sure. But they could also exist as plugins for a base, generic program that these tools snap into so that they can share data. For example, maybe the world generation tool could generate a map that has labeled cities, then, whenever that city is mentioned in the text or outline, it would appear as link for the author to store notes about what’s happened there.
Ideally, each piece of software would still be able to be function independently, but when ran together they could communicate and comfortably snap together into a better user interface with shared interactivity.
Arguably, this should actually be the job of the Operating System to provide this backend on which things can request to hook together and each program could expose generic interfaces, like a text editor saying “here’s my main text box, feel free to look through it for words to turn into links”, and all open programs could say “Yeah, I want to do that” - of course, provided the user wants to give programs permission to do so.
All of this would hopefully mean that any extension written for one program would work for another, and any program could talk to another. For example, currently the realm of music software has a little bit of this with VSTs and MIDI. but it still leaves a lot to be desired.
I’d actually like to take it a step further though and ask that all data of any kind use a common enough format that it can be processed with any extension/program written with this API in mind. Imagine if you could use a synthesizer as a static generator for image manipulation, or color management controls as an EQ.
Seriously. This idea just blows my mind. If we let data get re-intrepted as things it’s not supposed to be, the options are nuts.
Both would and should behave in strange way, and it’s this very lack of defined behavior that could lead to interesting art forms. I’d love to see a ‘Master’ API that works across all formats and ideas with a common data type that allows for program⟺program, program⟺extension, program⟺hardware, etc. communication even in long, complicated chains. After all, if you’ve taken a signals and systems course you know that basically any data can be treated as a signal.
As for what this would actually look like, having an operating system which presents - as a core to the functionality - some sort of node based programming system would work. While I don’t actually know how to use it, I think Enso demonstrates this concept fairly well:
If you’d like to try it, you’ll want to watch The tutorial video on YouTube.
Image taken from the Enso GitHub Repository
though there are plenty of other examples, like the node editors used for making shaders or programming in Unreal Engine.
Potentially this could also plug into the entire OS as well, making it so an image manipulation program’s extension could for example modify anything output to the screen in real time, or an audio program could effect the output of anything. For developer’s this may even offer more power, making possible things such as inter-process communication (think pipes, like $ls -la | grep png) a matter of connecting two nodes, or reading disk information such as activity, space, or even writeback and inode information, this would literally allow any one piece of information to be accessible to any other. This does have obvious permission issues, but unix permissions should already have this under control. If something like this could also be tied into the previously mentioned internet search and socialization ‘web’ without massive security concerns the potential use cases are as simple as getting color information from an image hosted online to as complicated as remote access or distributed computing.
This has already been tried to some extent with Pipeworld (GitHub), which bills itself as a “Dataflow ‘spreadsheet’ desktop environment”. There’s a demo of it on YouTube here, though you have to be pretty nerdy to fully appriciate it.
This also does already exist for some workflows. For example, video synthesis (while quite nieche) has Syphon which many video synthesis applications support for realtime frame sharing with minimal overhead.
Slightly more impressive from a more technical side is that you can reverse search for methods using an expected input-output pair
— Azlen Elza (@azlenelza) March 16, 2021
For example if you type in 'eureka', 'EUREKA' it will return the method "asUppercase" which performs that string operation!https://t.co/9DpmCuV9hf
Oh, and our systems are fucking racist and suck for anyone with special needs. #
Racist, how can a computer be racist? #
Well, okay, this depends on the definition of ‘racist’ I guess, but there’s definitely some issues. There’s the more mundane and debatable stuff such as using ‘Master/Slave’ to denote device control schemes or using the terms whitelist and blacklist for allowed and dis-allowed lists respectively, but those are all results of human naming decisions.
The bigger issue is with AI. There have been a ton of stories now where facial recognition software, used for test taking or by government and police, have built in racial biases as a result of learning the same racial biases that made up the data sets to begin with. This is, to put it extremely mildly, not great.
Special Needs? #
Well, yeah. How often do you see more common needs like color blindness accounted for, let alone issues like screen readers. If anything, some of these things are getting worse. For example, web design is becoming more and more JavaScript heavy, which can often result in screen readers just not being able to process much of the text on screen. Meanwhile, applications that everyone is expected to use are becoming complex enough, with more and more rarely used features being shoved into sub-menus that it’s harder to interact with them in non traditional ways.
Sure, we’re making better hardware to tackle these issues, but a lot of it is pretty expensive.
There’s also the problem of making computers accessible to people with metal handicaps. And I’ll be honest, this one’s rough. Just like how power tools are an extension of our ability to do physical works, computers, I think, are naturally an extension of the mind. If a subset of users have less capable minds to begin with, it’s going to be really hard to design around that.
I’m not the best to talk on these issues to begin with though as for the most part my body and mind don’t impede the way I work or require special tools. So, instead I’ll link to some other articles:
Software development 450 words per minute
Chapter 3 of ‘Buliding Accessible Websites’ by Joe Clark (I think this is written a bit… bluntly. I don’t agree with everything here. That said, it’s still a good resource)
Access #
While not an issue strictly pertaining to race or disability, there’s certainly a bias for those groups to also be poor or in worse circumstances that limit their internet connection or hardware’s speed. The solution? Stop making shit so fucking bloated. If you’re developing on a high end computer with umpteen cores and enough ram to store the English-only copy of Wikipedia (2) make sure to at least try it on something else and see if it still works.
We basically don’t even own our computers anymore #
Like many things in this far-to-long article, this could be post on its own, but I do think it’s necessary to bring up the fact that there’s an on going war against general purpose computation. If you’ve got an hour to kill (or half an hour if you can tolerate 2x speed), this video is basically required viewing:
A few notes on this video.
SOPA, the Stop Online Piracy Act, is mentioned because at the time it was a big deal. Thankfully, it was indeed stopped.
Illegal Numbers are a thing, and the history of them is incredibly interesting
There are also issues on ownership, for example:
Amazon Sued For Saying You’ve ‘Bought’ Movies That It Can Take Away From You and Microsoft Is Closing Its Ebook Store and Taking the Books With It
Not to mention the fact that updates keep changing how IOT devices work, making them more “needy” as they display more notifications and interupt the user more in a plea to get used (so they can harvest even more data).
Digital Conclusion #
So, clearly there’s room for improvment with how we interact with software and the core experiance with how we find, access, look at, store, transfer, and create digital content. Some of what I’ve sugessted here may seem far fetched and all but impossible, but the same feels true if we consider how advanced smart phones would seem in 1999 or some of today’s AI content generation still seems, as it gets better at generating life like images and holding convincing conversations.
I’m not the first to think on this subject by any means, Programs are a prison: Rethinking the fundamental building blocks of computing interfaces by Robert Lechte is a particularly good example of other thoughts on this same subject.
- ... unless that service is based around that permission, like denying a recording app access to a microphone.
- Currently 17.5Gb - https://dumps.wikimedia.org/enwiki/20201001/
[…]
- AnIdiotONTheNet comment on the Re-Thinking the Desktop OS Hacker News Submission